Diskussion:Zeichenkodierung
"Kodierung" oder "Codierung" ?[Quelltext bearbeiten]
Mein Herz hängt nicht dran, aber da unsere Mitmenschen ganz eindeutig "Code" gegenüber "Kode" bevorzugen, sollten wir vielleicht auch "Codierung" schreiben. Ich habe auch erst mit gemischten Lösungen experimentiert, dann aber gesehen, dass diese früher oder später zu hässlichen Inkonsistenzen führen. Weialawaga 17:58, 18. Aug 2004 (CEST)
- Zwar schreibt man eher Code (auch Kode geht), aber Kodierung ist doch viel lautgetreuer. Ich vermute, dass viele Codierung schreiben, weil sie dabei an Code denken. Es ist aber ein unschöne Mischform aus deutscher Wortendung und Fremdwort, also selbst sehr inkonsistent. Ich vermute, dass sich Code vom englischen code ableitet. Bei Kodierung bin ich mir da nicht sicher. Stern !? 18:12, 18. Aug 2004 (CEST)
- "lautgetreu" ist ein schlechtes Argument: wie man "c" vor "o" auszusprechen hat, ist wohl kaum zweifelhaft.
- Recherche unter "Deutsche Bücher" bei Amazon ergibt 70:18 für "Codierung".
- Niklas Luhmann, dem ich im Zweifel mehr vertraue als 69 anderen, schreibt "Codierung". -- Weialawaga 18:29, 18. Aug 2004 (CEST)
- Ich glaube mit "lautgetreu" ist nicht die Aussprache des "c" gemeint, sondern die des "o". Die meisten Leute, die ich kenne, sprechen "Code" nicht wie "Kod" aus, sondern wie das Englische "Code". Ich weiß auch nicht, was ich von "Code" halten soll, weil ich mich schon so daran gewöhnt habe.141.85.0.66 23:51, 14. Jul 2006 (CEST)
Zeichensatztabellen[Quelltext bearbeiten]
Unter Diskussion:Zeichenkodierung/Zeichensatztabellen warten etliche Tabellen auf Einbau in passende Spezialartikel. -- Weialawaga 18:29, 18. Aug 2004 (CEST)
What a Mess[Quelltext bearbeiten]
Eigentlich ist dieser Artikel zusammen mit "Code" ein riesiges Durcheinander von Begriffen, die im Deutschen (historisch bedingt) sowieso nicht sauber geklärt sind.
Code, Kodierung, encoding wird manchmal synonym, manchmal differenzierend verwendet. Das wäre (und war bis zum Unicode) kein Problem, wenn es nicht im englischen klare Differenzierungen gäbe:
Ein Zeichensatz (character set oder character repertoire) ist eine exakt festgelegte Menge S verschiedener Schriftzeichen.
Ein Zeichencode (ccs, coded character set) ist ein Zeichensatz S mit einer Abbildung zwischen den Schriftzeichen und einer Codemenge M (Byte, endliche Teilmenge der ganzen Zahlen ...). Die Menge M heißt auch codespace oder codepage mit dem diffizilen Unterschied, daß der codespace eher die Codemenge M und die codepage die Zeichenmenge S beschreibt.
Ein codepoint oder encoded character ist ein Element der Codemenge M.
Texte werden durch die Codepoints ihrer Schriftzeichen dargestellt.
In einfachen Fällen können die Codepoints direkt aneinandergereiht werden. Heute ist das meistens nicht mehr der Fall. Codepoints mit mehr als 8 Bit müssen ihre Bitmuster in definierter Form ablegen.
Die encoding form (gute deutsche Übersetzung nicht bekannt, cef, character encoding form, oft nur kurz encoding genannt) definiert, in wie große Bytegruppen ein Codepoint gespeichert wird und wie Codepoints, die die definierte Bytegruppe überschreiten, gespeichert werden können. Im UTF-8 werden Einzelbytes verwendet, UTF-16 speichert Codepoints in ein oder zwei 16-Bit-Variablen und UTF-32 kann alle heutigen Codepoints in einer 32-Bit-Variablen speichern. Die Variablen heißen auch code units.
Das encoding scheme (gute deutsche Übersetzung nicht bekannt, ces, character encoding scheme, oft nur kurz endianess genannt) definiert die Ablage der Variablen als Bytes im Speicher. In einfachen Fällen wird nur die Reihenfolge festgelegt (big-endian oder little-endian), jedoch sind auch platzsparende schemes definiert (SCSU, BOCU, Puniycode). Komplexe Schemes können zwischen mehreren Varianten wechseln (ISO/IEC 2022). Einfache Schemes werden manchmal am Anfang eines Textes als BOM (byte order mark) angezeigt (0xEF,0xBB,0xBF bei UTF-8, 0xFF, 0xFE bei little-endian, 0xFE, 0xFF bei big-endian).
Manchmal werden cef und ces zusammengefaßt, wie bei IANA mit den Bezeichnungen UTF-16BE und UTF-16LE. Hier sind BOMs verboten.
Ein Glyph ist aktuelle Darstellung eines einzelnen Schriftzeichens.
Beispiel: Das chinesische Schriftzeichen für Berg, shan, 山 hat im Unicode den Codepoint U+5C71 = 山. Mit UTF-16 als cef wird es als eine code unit abgelegt. Mit ces bigendian steht 5C, 71 im Speicher, mit littleendian 71, 5C. Mit UTF-8 stehen die drei units E5, B1, B1 im Speicher. Das Glyph ist 山.
Das müsste dringend und gut in die Artikel Code, Zeichenkodierung, Encoding eingearbeitet werden. Ich schrecke selbst davor zurück wegen a) Zeitmangel und b) die brauchbaren Teile (Morse...) würde ich erhalten und da kenne ich mich nicht gut aus. (falsch signierter Beitrag von Brf (Diskussion | Beiträge) 10:57 Uhr, 29. Nov. 2012)
- Da sich seit einem halben Jahr niemand geäußert hat, füge ich den zur Diskussion gestellten Teil an geeigneter Stelle im Artikel ein (falsch signierter Beitrag von Brf (Diskussion | Beiträge) 21:29 Uhr, 19. Jun. 2013)
Ohne diesen Absatz (von Brf) wäre der Artikel meiner Auffassung nach falsch. Das was der Artikelanfang als Zeichenkodierung definiert, (nämlich die hier beschriebenen "code points") ist meiner Auffassung nach alles Teil des Zeichensatzes. "Zeichenkodierung" ist imho mit "character encoding" bzw. in diesem Absatz benannt mit "encoding form" und encoding scheme" gleich zu setzen (also wie werden die Zeichen als bytes repräsentiert) und hat nichts mit dem character set oder den code points zu tun. (Abgesehen davon, dass die Zeichenkodierung definiert, wie ein Zeichensatz konkret als Bitfolge repräsentiert wird. Ob ein verarbeitendes System dann big endian, little andian oder noch ein andere Speicherorganisation verwendet ist hiervon unabhängig und nicht teil der Zeichenkodierung - auch wenn die Zeichenkodierung selbst ebenfalls eine "endianness" hat.) Vielleicht sollte man die Artikel Zeichenkodierung und Zeichensatz zusammen führen?
--62.206.237.210 18:06, 6. Apr. 2016 (CEST)
- Tja, der Artikel Zeichensatz grenzt sich bereits in seiner Einleitung vom Begriff "Zeichencode" ab. Da in der WP ein Lemma immer nur eine Bedeutung haben darf, ist für Zeichencode also ein eigener Artikel notwendig. Voilà.
- --arilou (Diskussion) 09:19, 7. Apr. 2016 (CEST)
Der Abschnitt Zeichensätze für Computersysteme im Artikel Zeichensatz sollte eigentlich nach Zeichenkodierung verschoben werden, da hier Beispiele verschiedener Kodierungen angeführt werden. Schöne Grüße --185.65.193.169 11:04, 9. Okt. 2018 (CEST)
Falsche Aussage: "Eine solche Bytefolge, die ein Zeichen darstellt, nennt man code unit."[Quelltext bearbeiten]
Im Abschnitt "Differenzierung der Begriffe durch Einführung des Unicodes" gibt es folgende Sätze:
- Mit encoding form (character encoding form, cef) bezeichnet man eine Abbildung der Codepunkte auf Bytefolgen. Jedem Codepunkt wird ein Byte oder eine Folge von mehreren Byte zugeordnet, wobei die Länge der Bytefolgen nicht für alle Codepunkte gleich sein muss.
- Eine solche Bytefolge, die ein Zeichen darstellt, nennt man code unit.
Das ist nicht korrekt. Eine Code unit kann je nach gewählter Kodierung, 1 Byte (UTF-8), 2 Byte (UTF-16), oder 4 Byte (UTF-32) sein. Die Anzahl der Code units die die Bytefolge ergeben, die wiederrum den Codepoint kodieren sind eine andere Sache. Diese Bytefolge (letzter Satz) ist nicht die code unit, sondern diese Bytefolge besteht aus code units!
Zeichenverschlüsselung vs. Zeichenkodierung[Quelltext bearbeiten]
Gibt es einen Bedeutungsunterschied zwischen den Begriffen Zeichenverschlüsselung und Zeichenkodierung oder können die Begriffe synonym verwendet werden?
In den nachfolgenden Links wird bspw. der Begriff Zeichenverschlüsselung benutzt:
- Zeichenverschlüsselung
- Zeichenverschlüsselung in Tabelle
- Zeichensatz und Zeichenverschlüsselung für die Elektronische Datenverarbeitung in Bibliotheken
Wäre vllt. im Artikel zu ergänzen.--2003:CF:3F05:E32B:DCF8:1A3A:67CC:371F 15:09, 20. Nov. 2020 (CET)
- Im Prinzip ist es erst einmal exakt dasselbe. ABER: "Zeichenkodierung" wird besser verstanden; bei "Zeichenverschlüsselung" denken unbedarfte Leser mitunter an einen kryptographischen Vorgang und denken, da würde irgend etwas mit Passwort usw. verborgen.
- Besser wäre so etwas wie "Zeichenvernummerung", aber da mit "Zeichenkodierung" ja bereits ein verbreiteter, viel besser verstandener Begriff vorhanden ist, kann man ja einfach vorzugsweise selbigen nutzen...
- --arilou (Diskussion) 13:30, 23. Nov. 2020 (CET)
- Ich war mal so frei, das in der Einleitung zu erwähnen. --arilou (Diskussion) 13:51, 23. Nov. 2020 (CET)
Zeichensatz (... character repertoire) char. repertoire ist was Anderes im engl. Art.[Quelltext bearbeiten]
Ein Zeichensatz (character set oder character repertoire) ist eine Menge S verschiedener Schriftzeichen.
Im engl.Art.:"The character repertoire is an abstract set of more than one million characters found in a wide variety of scripts including Latin, Cyrillic, Chinese, Korean, Japanese, Hebrew, and Aramaic."
Also ein Zeichensatz ist LATIN 1, oder GREEK. Aber ein "character repertoire" bezeichnet die gesamte Menge aller Zeichen die dargestellt werden können und somit mehrere Zeichensätze. Korrekt?
Was stimmt nun? Grüße! --2A02:3037:410:A07A:2C30:6AC3:176A:6ECD 19:20, 21. Jul. 2021 (CEST)
Bedeutungsinhalt der Begriffe: Zeichencode = codepoint?[Quelltext bearbeiten]
Unter dem Abschnitt "What a mess" hat @Brf einige Begriffe definiert, bei einem dieser Begriffe bin ich im Rahmen meiner eigenen Recherche auf eine Definition gestoßen, die sich von jener zu unterscheiden scheint, die @Brf angegeben hat. Der Begriff "Zeichencode" wird mit dem englischen Begriff "coded character set" gleichgesetzt.
@Brf schrieb folgendes:
"Ein Zeichencode (ccs, coded character set) ist ein Zeichensatz S mit einer Abbildung zwischen den Schriftzeichen und einer Codemenge M (Byte, endliche Teilmenge der ganzen Zahlen ...). Die Menge M heißt auch codespace oder codepage mit dem diffizilen Unterschied, daß der codespace eher die Codemenge M und die codepage die Zeichenmenge S beschreibt."
Allerdings ist in einem anderen Artikel zu lesen, dass es sich bei dem "Zeichencode" um eine Nummer handelt die einem bestimmten Zeichen zugeordnet wurde, dementsprechend wäre der Begriff "Zeichencode" vielmehr mit dem englischen Begriff "codepoint" gleichzusetzten.
Der Artikel auf den ich mich hier beziehe ist auf der Internetseite WC3 (World Wide Web Consortium) zu finden, hier ist der Link dazu:
https://www.w3.org/International/questions/qa-what-is-encoding
Verfasser des besagten Artikels ist ein gewisser Herr Richard Ishida, welcher den Artikel in seiner mutmaßlichen Muttersprache Englisch verfasst hat, der oben angeführte Link jedoch führt zu einer deutschen Übersetzung des Artikels. Als Übersetzer wird eine Person mit dem Namen Gunnar Bittersmann genannt.
Wenn man dem genannten Artikel glauben schenkt, dann bezeichnet der Begriff "Zeichencode" nicht etwa die Gesamtheit der zugeordneten Codepoints aus der Codemenge zu all den Zeichen des Zeichensatzes, sondern er bezeichnet den Code für ein bestimmtes Zeichen.
Ein weiteres Argument dafür, dass der Begriff "Zeichencode" nicht mit dem Begriff "coded character set" gleichzusetzten ist, ist der, dass der Begriff "Zeichencode" bei Microsoft Word Anwendung findet und dort ebenfalls unmissverständlich einen Code (Codepoint) bezeichnet.
Auf diesem Bild ist ein Fenster zu sehen, dass zeigt wie Word diesen den Begriff "Zeichencode" versteht:
https://www.computerwissen.de/fileadmin/content/Word-Symbol-Tastenkombination.png
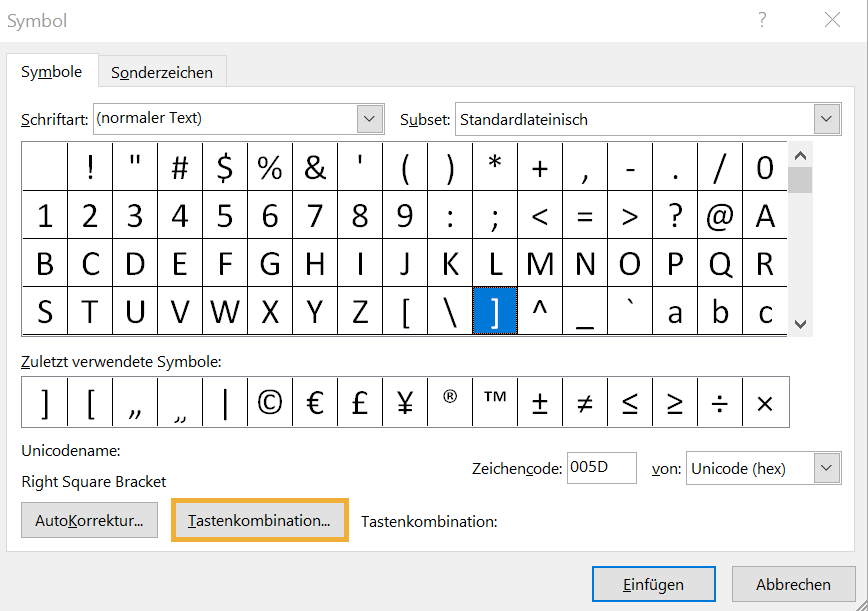{kind=link}
--Lorenor Zoro (Diskussion) 14:59, 26. Mai 2023 (CEST)
Jvo.8 --2003:C9:738:E400:E168:2019:1334:DB0D 10:42, 9. Apr. 2024 (CEST)