Räumliche Autokorrelation
Räumliche Autokorrelation wird in der Geostatistik verwendet, um Zusammenhänge von räumlichen Einheiten zu identifizieren, zu messen und auf ihre statistische Signifikanz zu testen.
Begriff und Definition[Bearbeiten | Quelltext bearbeiten]
Der Begriff „Auto-Korrelation“, übersetzt "Beziehung mit sich selbst", bezieht sich auf das Auftreten von Ausprägungen einer Variable an bestimmten Orten in Abhängigkeit von der Ausprägung derselben Variable an anderen Orten.[1] Eine ältere "sprechende" Bezeichnung im Deutschen für das Phänomen ist Räumliche Erhaltensneigung[2]. Dieser ältere Begriff spielt darauf an, dass die Werte einer räumlich autokorrelierten Variable dazu neigen, ähnliche Beträge zu zeigen, wenn die Orte, an denen sie gemessen wurden, im Raum näher bei einander liegen.
Abgrenzung zu Korrelation und zeitlicher Autokorrelation[Bearbeiten | Quelltext bearbeiten]
Bei der Berechnung der statistischen Korrelation werden zwei Variablen (x,y) bei zwei oder mehr Beobachtungen betrachtet; bei der räumlichen Autokorrelation hingegen eine Variable x an zwei oder mehr Orten.[3]
Während die zeitliche Autokorrelation die Beziehungen der Ausprägungen einer Variablen mit sich selbst über die Zeit beschreibt, beschreibt die räumliche Autokorrelation die Ausprägungen einer Variablen mit sich selbst im Raum.
Berechnung[Bearbeiten | Quelltext bearbeiten]
Räumliche Autokorrelation kann positive oder negative Ausprägungen haben:
- Positive räumliche Autokorrelation liegt dann vor, wenn nahe beieinander liegende Orte einander mit höherer Wahrscheinlichkeit ähnlich sind als weiter voneinander entfernte Orte.[4] Das heißt: Positive räumliche Autokorrelation liegt vor, wenn Orte dazu tendieren, im Hinblick auf eine Eigenschaft Cluster zu bilden. Positive räumliche Autokorrelation ist eine empirische Manifestation von Toblers „Erstem Gesetz der Geographie“.
- Negative räumliche Autokorrelation liegt dann vor, wenn benachbarte Orte auffällig - im Vergleich zu Zufallseffekten[5] - unterschiedliche Eigenschaftswerte aufweisen. Bei Phänomenen, die mit Lebewesen (Tieren, Pflanzen) verbunden sind, wird negative Autokorrelation häufig durch Wettbewerb und Verdrängung verursacht[6].
- Keine räumliche Autokorrelation liegt vor, wenn die Orte im Hinblick auf eine Eigenschaft zufällig angeordnet sind, also keine ausgeprägten Cluster aufweisen.
Grundlage der Betrachtung ist eine räumliche Analyse von Punkten oder Polygonen und der Aufbau einer Distanzmatrix zwischen den Punkten oder Polygonen. Bei Punkten werden in der Regel entweder der Euklidische Abstand oder der Abstand nach der Manhattan-Metrik verwendet. Bei Polygonen wird entweder ein Zentralpunkt ermittelt und wie bei Punkten verfahren oder es wird lediglich festgestellt, ob Polygone einander benachbart sind (dann wird der Wert 1) oder nicht (0). Die Nachbarschaftsbeziehung kann sich auf das Vorhandensein von gemeinsamen Kanten (Linien) und Punkten (Queen Contiguity) oder auf das Vorhandensein allein von gemeinsamen Kanten (Rook Contiguity)[7] oder auf die Definition der k nächstgelegenen Nachbarn mit 1 (und aller übrigen mit 0, siehe Nächste-Nachbarn-Klassifikation) beziehen.
Kennziffern[Bearbeiten | Quelltext bearbeiten]
Globale Maße[Bearbeiten | Quelltext bearbeiten]
Wichtige Kennziffern[8] für die Messung räumlicher Autokorrelation in einem größeren Raum („globale Betrachtung“) sind
- der vom australischen Mathematiker Patrick Alfred Pierce Moran (1917–1988) entwickelte Indexwert I (Moran's I)
- der von dem irischen Statistiker Roy Geary (1896–1983) entwickelte Index C (Geary's C)
„Global “bedeutet hier, dass ein Wert für den gesamten Betrachtungsraum berechnet wird. Neben I und C kann auch eine von Getis und Ord entwickelte generalisierte Form des Index G (General G-Statistic) verwendet werden.
Moran's I[Bearbeiten | Quelltext bearbeiten]
Zur Berechnung von Moran's I[9] wird zunächst die räumliche Autokovarianz der Variable x in zwei Regionen i und j ermittelt und über alle Regionenpaare i,j summiert. Zur Berechnung der Autokovarianz wird zunächst in der Region i die Differenz zwischen dem Wert der Variable x in dieser Region und dem Mittelwert der Variable x über alle Regionen gebildet. Das Ergebnis ist entweder positiv oder negativ. Das Gleiche geschieht in der Region j. Die Ergebnisse werden multipliziert. Diese Rechnung erfolgt für alle Regionenpaare i und j, die Ergebnisse werden summiert:

Das Gewicht w beschreibt die räumliche Nähe oder Distanz der beiden Regionen. Häufig wird für w der Wert 1 gewählt, wenn die Regionen benachbart sind und 0 wenn nicht. w macht also aus der Autokovarianz eine räumliche Autokovarianz.
Zur vollständigen Berechnung von Moran's I wird die so ermittelte räumliche Autokovarianz an der Summe der quadrierten Abweichungen der Region i und einem Beziehungswert normiert:[10]

Moran's I kann Werte von −1 bis +1 annehmen, Werte größer als +0,3 werden als Indikator für eine relativ starke positive Autokorrelation angesehen, Werte kleiner als −0,3 als Indikator für eine relativ starke negative Autokorrelation.[11] Eine inferenzstatistische Absicherung durch Vergleich der standardisierten I-Werte mit einer Standard-Normalverteilung oder anhand eines Permutationstests ist üblich.
Der Erwartungswert für Moran's I bei Zufall beträgt[12]:

- Räumliche Verteilungen von binären und kontinuierlichen Variablen mit ihrem Moran's I-Wert
-
 Dispers verteilt, Moran's I ist −1
Dispers verteilt, Moran's I ist −1 -
 Ziemlich dispers verteilt, Moran's I ist negativ
Ziemlich dispers verteilt, Moran's I ist negativ -
 Zufällig verteilt, Moran's I nahe 0
Zufällig verteilt, Moran's I nahe 0 -
 Zufällig verteilt, Moran's I nahe 0
Zufällig verteilt, Moran's I nahe 0 -
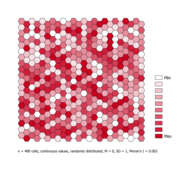 Zufällig verteilt, Moran's I nahe 0
Zufällig verteilt, Moran's I nahe 0 -
 Moderat geclusterd, Moran's I ist positiv
Moderat geclusterd, Moran's I ist positiv -
 Vollständig geclustered, Moran's I nahe +1
Vollständig geclustered, Moran's I nahe +1







Geary's C[Bearbeiten | Quelltext bearbeiten]
Geary's C[13] folgt einer ähnlichen Logik, allerdings wird nicht die Autokovarianz, sondern die Summe der quadrierten Abweichungen zugrunde gelegt und die Normierung etwas angepasst:

Geary's C kann Werte von 0 bis 2 annehmen, mit Werten < 1 als Indikator für eine positive räumliche Autokorrelation und > 1 als Indikator für negative räumliche Autokorrelation. Der Erwartungswert von Geary's C bei Zufall ist 1[14]. C ist im Vergleich zu Moran's I empfindlicher gegenüber kleinräumlichen Variationen und wird seltener genutzt.[15]
Lokale Maße[Bearbeiten | Quelltext bearbeiten]
Für die Betrachtung von einzelnen Gebieten („lokale Betrachtung“) werden häufig
- die von dem US-amerikanischen Geographen Arthur Getis und dem ebenfalls US-amerikanischen Betriebswirt J. Keith Ord entwickelten Indizes Gi und Gi* für die Analyse von Hotspots[16] oder
- die von dem US-amerikanischen Geographen Luc Anselin entwickelten „Lokalen Indikatoren des räumlichen Zusammenhangs“[17] (Gamma, Local Moran's I und Local Geary's c) für die Analyse von Clustern
genutzt. „Lokale “Betrachtung bedeutet hier, dass nicht ein Index-Wert für alle betrachteten Orte berechnet wird, sondern für jeden Ort ein eigener Indexwert. Die lokalen Indexwerte geben also nicht Auskunft über die räumliche Konstellation insgesamt, sondern über die Stellung eines Ortes i innerhalb der räumlichen Konstellation. Während die globalen Maße also aussagen, ob es räumliche Cluster gibt, geben die lokalen Maße an, wo sich diese befinden.[18]
Getis-Ord G[Bearbeiten | Quelltext bearbeiten]
Die G-Statistik von Getis und Ord ist ein inferenzstatistisches Maß der lokalen räumlichen Autokorrelation.[19] Der Wert G für einen Punkt i ergibt sich aus den Werten aller Punkte j, die innerhalb einer definierten Distanz d liegen. Das Gewicht w wird 1 für alle Punkte innerhalb der Distanz d und 0 für alle anderen Punkte und den Punkt i selbst. G ist nur definiert für den Fall, dass i und j nicht identisch sind, andernfalls wird statt Gi der leicht abgewandelte Index Gi* verwendet. Für jedes i werden ein p-Wert und ein z-Wert berechnet, die Auskunft über die Bedeutung des I-Wertes geben (z. B. High-High-Cluster mit signifikant hohen Werten in einer Nachbarschaft mit anderen hohen Werten). Hohe z-Werte deuten auf sogenannte „Hotspots“, niedrige z-Werte auf „Coldspots “hin.

Local Moran's I[Bearbeiten | Quelltext bearbeiten]
Local Moran's I ist ebenfalls ein inferenzstatistisches Maß der räumlichen Autokorrelation[20]. Für jedes i werden ein p-Wert und ein z-Wert berechnet, die Auskunft über die Bedeutung des I-Wertes geben (z. B. High-High-Cluster mit signifikant hohen Werten in einer Nachbarschaft mit anderen hohen Werten). Die Berechnung erfolgt, wie beim globalen Moran's I, durch Iteration über alle Kombination von Orten.

Software[Bearbeiten | Quelltext bearbeiten]
Räumliche Autokorrelationen können mit allen gängigen Geoinformationssystemen (GIS), ggf. mit Hilfe von Plug-Ins, berechnet werden.[21] Außerdem können Spezialanwendungen für die räumliche Statistik wie zum Beispiel GeoDA oder CrimeStat[22] verwendet werden.
Literatur[Bearbeiten | Quelltext bearbeiten]
- George Grekousis: Spatial Analysis Methods. Cambridge University Press, Cambridge / New York / Melbourne 2020, ISBN 978-1-108-49898-2 (englisch).
- David O'Sullivan, David J. Unwin: Geographic Information Analysis. 2. Auflage. John Wiley & Sons, Hoboken, NJ 2010, ISBN 978-0-470-28857-3 (englisch).
Einzelnachweise[Bearbeiten | Quelltext bearbeiten]
- ↑ John Odland: Spatial Autocorrelation. Sage Publ., London 1988, S. 7 (englisch, wvu.edu – auch als Onlineedition vom Sept. 2020 verfügbar): “Spatial autocorrelation exists whenever a variable exhibits a regular pattern over space in which its values at a set of locations depend on values of the same variable at other locations.”
- ↑ Josef Nipper, Ulrich Streit: Zum Problem der räumlichen Erhaltensneigung in räumlichen Strukturen und raumvarianten Prozessen. In: Geographische Zeitschrift. Band 65, Nr. 4, 1977, S. 241–263.
- ↑ George Grekousis: Spatial Analysis Methods. Cambridge University Press, Cambridge / New York / Melbourne 2020, ISBN 978-1-108-49898-2, S. 208 (englisch): “While statistical correlation refers to two distinct variables with no reference to location, spatial autocorrelation refers to the value of a single variable at a specific location in relation to the values of the same variable at neighboring locations.”
- ↑ David O'Sullivan, David J. Unwin: Geographic Information Analysis. 2. Auflage. John Wiley & Sons, Hoboken, NJ 2010, ISBN 978-0-470-28857-3, S. 35 (englisch).
- ↑ Der Entwickler von GeoDa, Luc Anselin, gibt in einem Videokurs eine gute Einführung in das Konzept der „spatial randomness“, siehe: Luc Anselin: Week 4a: Spatial autocorrelation (Introduction to Spatial Data Science). 29. März 2021, abgerufen am 17. August 2022 (englisch).
- ↑ Marie Fortin, Mark Dale: Spatial Analysis. A Guide for Ecologists. 2. Auflage. Cambridge University Press, Cambridge 2014, ISBN 978-0-521-19430-3, S. 34.
- ↑ Luc Anselin: Contiguity-Based Spatial Weights. In: GeoDa–An Introduction to Spatial Data Science. 2. Oktober 2020, abgerufen am 4. August 2022 (englisch).
- ↑ Yanguang Chen: An analytical process of spatial autocorrelation functions based on Moran’s index. In: PLOS ONE. Band 16, Nr. 4, 2021, doi:10.1371/journal.pone.0249589.
- ↑ P.A.P. Moran: Notes on Continuous Stochastic Phenomena. In: Biometrika. Vol. 37, No. 1/2, 1950, S. 17–23, doi:10.2307/2332142, JSTOR:2332142.
- ↑ ein illustratives Beispiel liefert: „ritvikmath“: Moran's I : Data Science Concepts. 28. September 2020, abgerufen am 14. August 2022 (englisch).
- ↑ David O'Sullivan, David J. Unwin: Geographic Information Analysis. 2. Auflage. John Wiley & Sons, Hoboken, NJ 2010, ISBN 978-0-470-28857-3, S. 206 (englisch).
- ↑ Mark Dale, Marie-Josée Fortin,: Spatial Analysis. A Guide for Ecologists. 2. Auflage. Cambridge University Press, Cambridge 2014, ISBN 978-0-521-19430-3, S. 145.
- ↑ Roy C. Geary: The Contiguity Ratio and Statistical Mapping. In: The Incorporated Statistician. Vol. 5, No. 3, 1954, S. 115–141, doi:10.2307/2986645, JSTOR:2986645.
- ↑ Mark Dale, Marie-Josée Fortin: Spatial Analysis. A Guide for Ecologists. 2. Auflage. Cambridge University Press, Cambridge 2014, ISBN 978-0-521-19430-3, S. 146.
- ↑ George Grekousis: Spatial Analysis Methods. Cambridge University Press, Cambridge / New York / Melbourne 2020, ISBN 978-1-108-49898-2, S. 217 (englisch).
- ↑ Arthur Getis, John Keith Ord: The analysis of Spatial Association by Use of Distance Statistics. In: Geographical Analysis. Band 24, Nr. 3. Ohio State University Press, Juli 1992, S. 190–192.
- ↑ Luc Anselin: Local Indicators of Spatial Association - LISA. In: Geographical Analysis. Band 27, Nr. 2. Ohio State University Press, Februar 1995, S. 97–101.
- ↑ George Grekousis: Spatial Analysis Methods. Cambridge University Press, Cambridge / New York / Melbourne 2020, ISBN 978-1-108-49898-2, S. 222 (englisch).
- ↑ Arthur Getis, J. Keith Ord: The Analysis of Spatial Association by Use of Distance Statistics. In: Geographical Analysis. Vol. 24, No. 3, Juli 1992, S. 189–206, doi:10.1111/j.1538-4632.1992.tb00261.x.
- ↑ Luc Anselin: Local Indicators of Spatial Association–LISA. In: Geographical Analysis. Vol. 27, No. 2, 1995, S. 93–115, doi:10.1111/j.1538-4632.1995.tb00338.x.
- ↑ vgl. z. B. für ArcGIS: ESRI: Funktionsweise von räumlicher Autokorrelation (Global Moran's I). In: ArcGIS Pro 3.0 Werkzeugreferenz. Abgerufen am 15. August 2022.
- ↑ National Institute of Justice: CrimeStat: Spatial Statistics Program for the Analysis of Crime Incident Locations. In: nij.ojp.gov. 11. Dezember 2019, abgerufen am 4. August 2022 (englisch).